













Leveraging AI Requires Finesse, But Delivers Huge Rewards
By Fred Aminzadeh
Artificial intelligence is accelerating efficiency gains and enabling smarter decisions at every stage in a field’s life. Its potential applications begin with exploration, drilling and field development, then extend to optimizing artificial lift systems and enhanced oil recovery programs.
Our industry is only one of many that is exploring AI’s potential. From health care, manufacturing and defense to entertainment and marketing, people in other industries are using AI to streamline repetitive tasks and uncover new insights.
While many of AI’s key tools have existed for decades, today’s computing power has made them more effective and accessible. Like traditional data analytics techniques, AI almost always involves examining the available information to make better decisions. However, rather than presenting that data to humans and requiring them to act on it, AI-driven software agents can make decisions autonomously.
When they are designed and deployed carefully, these agents can yield huge time savings and remarkably consistent results. To augment their capabilities, some AI agents are trained using machine learning techniques, which teach them to make predictions based on past experience.
Deep learning, a subset of machine learning, uses complex neural networks to simulate the way humans learn, allowing the AI to discover how to recognize features and patterns of interest. This capability can be invaluable in seismic analysis, but it has many other use cases within oil and gas.
Figure 1 lists domains across exploration, drilling and production where AI and data analytics can improve processes and reduce costs. During exploration, AI-DA can help companies interpret subsurface images, evaluate potential reserves, rank prospects, assess risks and pinpoint the best exploratory drilling locations.
FIGURE 1
Applications for AI Across the Upstream Sector
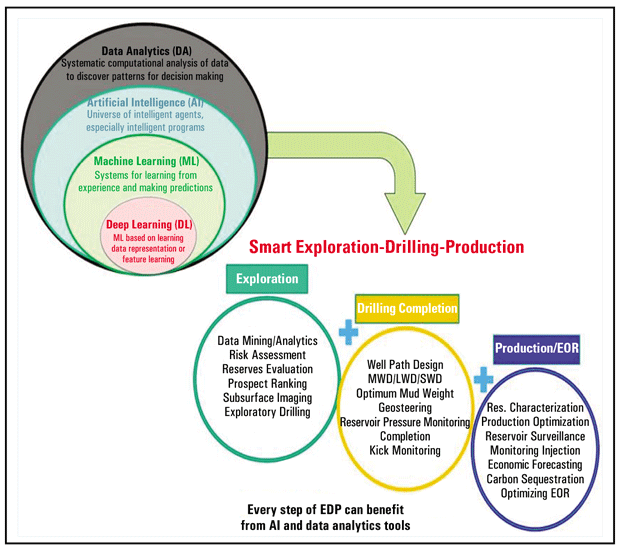
Once drilling begins, AI-DA can help optimize well paths and convert data from measurement-while-drilling, logging-while-drilling and seismic-while-drilling systems into real-time observations. This is one way that AI-based tools assist teams with selecting the best mud weight, geosteering and maintaining well control.
AI can provide similar guidance to completion engineers. And once the well begins producing, AI can simplify reservoir characterization workflows and give teams the information they need to optimize performance. This capability becomes increasingly important as a field ages and the operator must design, implement and monitor water, carbon dioxide or steam injection programs.
One of AI’s strengths is that it can consider many factors at once. In addition to making recommendations that are technically sound, many AI tools can assess the economic benefits and risks associated with a given path forward.
Prerequisites for Success
For AI to deliver meaningful insights, it needs data. Fortunately, the amount of data the industry collects has exploded as storage, transmission and processing costs have fallen.
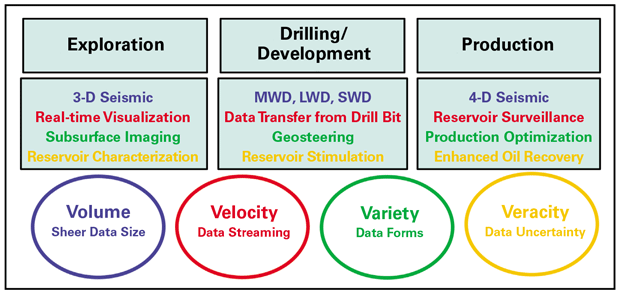
As data volumes continue to grow, it will become increasingly important to understand how to maintain and use that data. One of the key principles of big data science is that volume alone is not enough. Instead, those who want to harness vast datasets must consider three other Vs:
- Velocity, which represents how quickly data must be received and analyzed;
- Variety, meaning how many different data types are involved; and
- Veracity, a measure of the data’s accuracy and trustworthiness.
Companies’ infrastructure needs to be capable of handling the four Vs. For example, the storage must be able to accommodate a large amount of data (i.e. volume) and support different types and formats (i.e. variety) of heterogeneous data. The input-output layers integrated with this storage must be able to process different streams of data (i.e. velocity), as well as handling data with different levels of uncertainty (i.e. veracity).
Figure 2 color-codes several oil and gas areas to highlight the V that is most important for data from that space. In the exploration space, seismic acquisition involves huge volumes of data, represented by blue. Visualizing data in real-time necessitates a high velocity for data analysis, represented by red. Subsurface imaging integrates several different forms of data, bringing variety (green) to the forefront. And reservoir characterization involves managing uncertainty and therefore considering the veracity (gold) of various data sources.
FIGURE 2
The 4Vs of Big Data in Oil and Gas
Whatever the application, before starting a data science project, it is imperative to perform statistical and visual inspection to better understand the data. This analysis should also help determine if the data needs to be cleansed, which entails identifying inaccurate or corrupt segments of the data, then editing it or removing it from the dataset. Cleansing can be tedious, but it is vital for any analysis based on the data to be reliable.
Because trustworthy data is so important, organizations should do what they can to ensure the data they collect is accurate from the start. In many applications, AI tools can help maintain data quality by spotting and either highlighting or correcting extreme values or common errors. Sometimes AI can even fill in gaps in data by predicting likely values. In this sense, one AI tool can prepare data for analysis by other AI tools.
Neural Networks
Artificial neural networks (ANNs) are among the most common AI tools. Based on the structure of biological neurons, ANNs adopt several natural learning processes and undergo training, much as humans do. Several types of ANNs exist, including multi-layer perceptrons, self-organizing networks, radial basis function neural networks, modular neural networks (also known as committee machines), generalized regression networks, convolutional neural networks, generative adversarial networks, Kohonen networks and recurrent neural networks.
Explaining the differences between these techniques and describing their strengths, weaknesses and ideal use cases would take more space than I have here. The important point is that ANNs have proven to be effective in a variety of oil and gas applications. They have many attractive features that make them prime candidates for solving this industry’s complex problems.
First, ANNs can be extremely flexible. Like the human brain, they learn from experience and extrapolate lessons to new situations, which enables them to adapt to unforeseen events. This adaptability means that ANNs excel at dealing with faults or data that is inconsistent and noisy, an extremely common occurrence in the oil field.
Also, ANNs have a highly parallel structure. Instead of processing the entire data stream in sequence, they can break it up into chunks and look at several chunks in parallel or simultaneously, a capability that boosts performance, especially when using parallel processors. In practice, that means ANNs can quickly extract relevant properties from huge datasets or perform more intricate tasks without requiring excessive investments in computing power.
Because of their flexibility, ANNs can learn and model nonlinear and complex relationships without requiring those relationships to be explicitly defined. This benefit is extremely important, because in real life, many of the relationships between inputs and outputs are nonlinear and too complex to be expressed through simple equations.
ANN Structures
In general, artificial neural networks are collections of relatively large numbers of processing elements, called nodes or neurons, that are configured in a regular architecture. Figure 3a shows a typical ANN with input, internal and output nodes. The input nodes receive information from external sources, the internal nodes evaluate it, and the output nodes share the results of those evaluations.
FIGURE 3
Neural Networks’ Structure
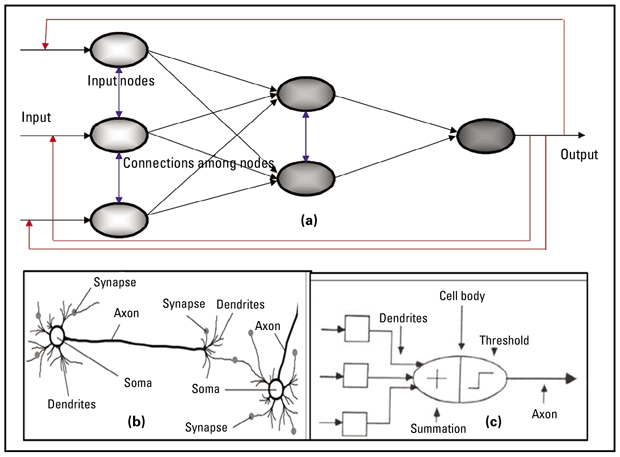
The figure includes lines representing how information moves between nodes. Depending on how the nodes connect, the ANN will fall into one of three categories. With only black connections, data passes from the input nodes to the internal nodes before reaching the output nodes, a structure called feedforward. Feedforward ANNs work well for tasks that involve processing information without requiring any “feedback,” such as reading the header information in an old well log or performing routine clustering of seismic attributes.
With the red connections, the structure transforms into a feedback ANN. This structure allows assessments from the output nodes to be sent back to the network and used to guide the next evaluation, a necessary capability for applications that involve using the preliminary results to further refine them. For example, a feedback ANN could be used to solve different seismic inversion problems.
Add the blue connections to the black and red sets, and the output nodes are no longer the only ones capable of sharing assessments. Even neurons within the same layer can communicate with each other. Such communication has been found useful in many oil and gas applications, including predicting permeability in tight sands and applying the “transfer learning” operation from one field to another for fault characterization when there is limited data available.
Biological Inspiration
The nodes within each structure resemble the biological neurons in the human brain. To illustrate this similarity, Figure 3b shows a biological neuron’s components. The cell body (soma) receives messages from other neurons through dendrites and sends messages to those neurons using axons. To reach their destination, these messages must travel across synapses linking the neuron to other cells.
For comparison, Figure 3c presents an artificial neuron. Because it receives signals from other neurons, the “summation function” can be compared to a dendrite. The “activation function,” the axon equivalent, looks at the information the summation function received to produce an output that it shares with other neurons.
Notice that most neurons receive input from several of their peers. During training, they learn how much weight to give the various inputs by experimenting with different weights and comparing the resulting predictions to known data. In theory, the more accurate the predictions are, the closer they are to the right weight.
For that theory to prove true, the training set needs to be carefully constructed to ensure that the data it contains resembles the data the neural network will need to analyze. If the training data has eccentricities or comes from a region that differs greatly from the region of interest, the neural network’s attempts to generalize the lessons it learned during training will lead to inaccurate results.
The bright side is that AI can recognize relationships that are far too subtle or complex for us to figure out on our own. It’s also tireless. Give it the right training data and sufficient computing power, and AI can tackle tedious and complex analyses with speed, consistency and endurance no human can match.
Practical Applications
AI’s ability to handle huge datasets can be a significant boon in exploration programs, which require vast quantities of data to be integrated. In most cases, the data comes from numerous sources that vary in scale, uncertainty level and resolution, as well as the environment they were collected in.
FIGURE 4
A Typical Data Pyramid for Exploration
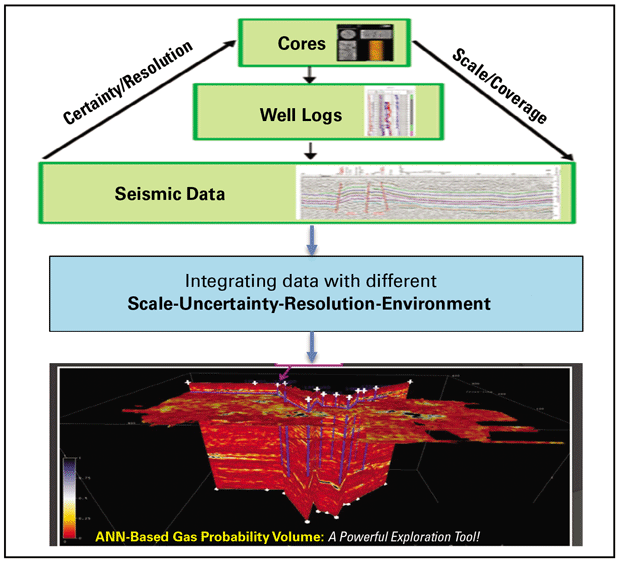
Figure 4 shows a typical data pyramid with core data at the top, log data in the middle and seismic data at the bottom. The data’s scale increases from top to bottom, as does the area the data covers. On the other hand, the resolution and level of certainty associated with the data increases toward the top. Integrating data with such drastic differences in Scale, Uncertainty, Resolution and Environment is very difficult. I refer to it as the SURE challenge.
With its ability to look at vast datasets and weigh how much each type of data available contributes to the outcomes it cares about, AI excels at navigating the SURE challenge. This is not a theoretical claim. I have seen numerous examples where smart teams have used AI to convert oceans of raw data into useful information.
As a case in point, some colleagues and I used an artificial neural network to integrate data from the Grand Bay Field in the Gulf of Mexico and create the gas probability map shown below the pyramid. To do so, the ANN weighed the significance of different seismic attributes and log data based on the training data information. Had we tried to create the map using traditional methods, it would have taken much longer with less accurate results.
Real-Time Updates
In many applications, AI can empower teams to make better decisions by accelerating modeling. As an example, imagine a typical enhanced oil recovery project based around injecting carbon dioxide. To optimize injection, improve performance and mitigate risks, the operator needs to understand how the reservoir is responding to injection over time, which requires dynamically updating the subsurface model.
FIGURE 5
Recursive Model of Fracture Evolution from CO2 Injection
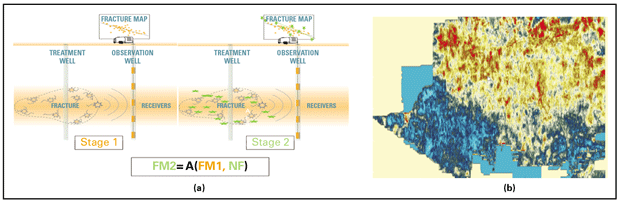
For best results, model updates should happen in near-real time. Even with modern high-performance computing and efficient algorithms, it would be impractical to create models from scratch every time a change occurs. However, we can revise the existing model by pairing AI with a fast recursive updating technique borrowed from control theory.
Recursive updating uses the old model, the latest input data and feedback parameters to constantly create a new model. The process involves:
- Collecting data;
- Creating a preliminary model of the system by relating the input data to the output or model parameters;
- Measuring new data; and
- Updating the model by using the new data and an “innovation process” that incorporates adaptive control principles.
An application of this approach for updating the fracture system from micro seismic data before and after different intervals of CO2 injection is shown in Figure 5a. In this case, the slope of the fracture grouping at the top of “stage 1” of injection gets steeper at the second stage of injection, a change that may indicate increased risk of induced seismicity from the new injection. The stage 2 fracture map (FM2) is calculated “recursively,” using a nonlinear operator (A), based on the stage 1 fracture map (FM1) and the new fractures (NF).
Figure 5b shows an AI-based fracture model updating based on 3-D seismic and microseismic data collected as part of the Decatur project in the Illinois Basin. In the upper right corner, the orange and yellow areas reveal some updated fracture patterns, while some of the fault pattern updates are shown in red.
The gas probability map and recursive model presented above represent a small fraction of the potential use cases for AI within exploration, drilling and production. At almost every stage of a field’s life cycle, AI can reduce costs and uncertainties while improving performance.
AI’s impact will only grow with time. That’s partly because the AI algorithms themselves are improving. At the same time, new tools are making it easier to apply those algorithms. And the more those algorithms see use, the more people learn about their strengths and limitations.
In the oil and gas industry, one of the biggest drivers of AI’s growing popularity is the complexity of the problems we face. As we overcome today’s performance limiters and seek to identify new ones, we will almost certainly need to understand the subsurface with greater nuance, a task that will require us to analyze increasingly vast and diverse data. By processing that data quickly and accurately, AI will help the oil and gas industry take its next step forward.
Editor’s Note: This article draws in part from Artificial Intelligence and Data Analytics for Energy Exploration and Production, a 584-page book that the author co-wrote with Cenk Temizel and Yasin Hajizadeh.

FRED AMINZADEH is the founder, president and chief executive officer of FACT Inc., a software and service company. Aminzadeh also is a co-founder and board member of Energy Transition International Inc., which applies artificial intelligence and fluid monitoring techniques to support enhanced oil recovery, carbon storage, geothermal and lithium projects. He was a member of the U.S. Department of Energy and National Energy Technology Laboratory’s SMART (Science-Informed Machine Learning for Accelerating Real-Time Decisions in Subsurface Applications) Initiative, a 10-year project that aims to significantly improve field-scale carbon storage and unconventional oil and gas operations by using machine learning.
Aminzadeh served as president of the Society of Exploration Geophysicists from 2007-2008. In 2018, SEG named him an honorary member in recognition of his contributions to the industry, including pioneering work on using neural networks and fuzzy logic within oil and gas. During his 40-year career, Aminzadeh spent 20 years at Unocal (now part of Chevron) and 10 years as president of the Americas division for dGB, the developer of the OpendTect platform.
For other great articles about exploration, drilling, completions and production, subscribe to The American Oil & Gas Reporter and bookmark www.aogr.com.

